В последние месяцы мировые СМИ пестрят заголовками об ИИ-генераторах изображений, позволяющих синтезировать картинки на основе текстовых подсказок. Впрочем, исследователи в сфере машинного обучения решили не останавливаться на достигнутом и взялись за покорение нового рубежа – генераторов видео. Среди них Deep Learning-инженеры материнской организации Facebook, Instagram, WhatsApp и Oculus – Meta, которые разработали новую систему Make-A-Video.

Как следует из названия, ИИ-модель Make-A-Video позволяет генерировать короткие видео на основе краткого описания каких-либо сценариев. Произведённые таким образом видео пока выглядят достаточно сыро: объекты в кадре нередко получаются размытыми, а их движения – искажёнными. Тем не менее подобная технология представляет собой важный шаг в развитии отрасли синтезирования ИИ-контента. В рамках анонса системы представители Meta заявили, что исследование в этом направлении расширяет возможности творческого самовыражения, позволяя создавать уникальные визуальные работы на основе нескольких слов или фраз. По словам Марка Цукерберга, Make-A-Video олицетворяет собой невероятный прогресс в покорении современных технологий, ведь системе приходится не только правильно генерировать каждый пиксель, но также просчитывать, как они будут изменяться с течением времени.
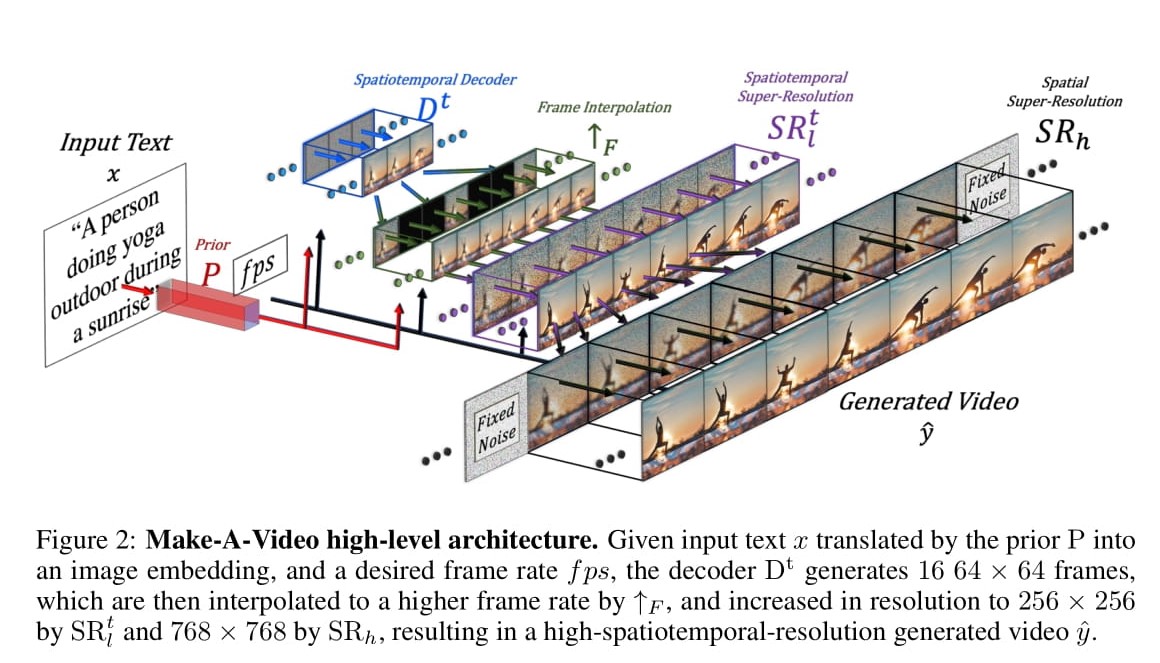
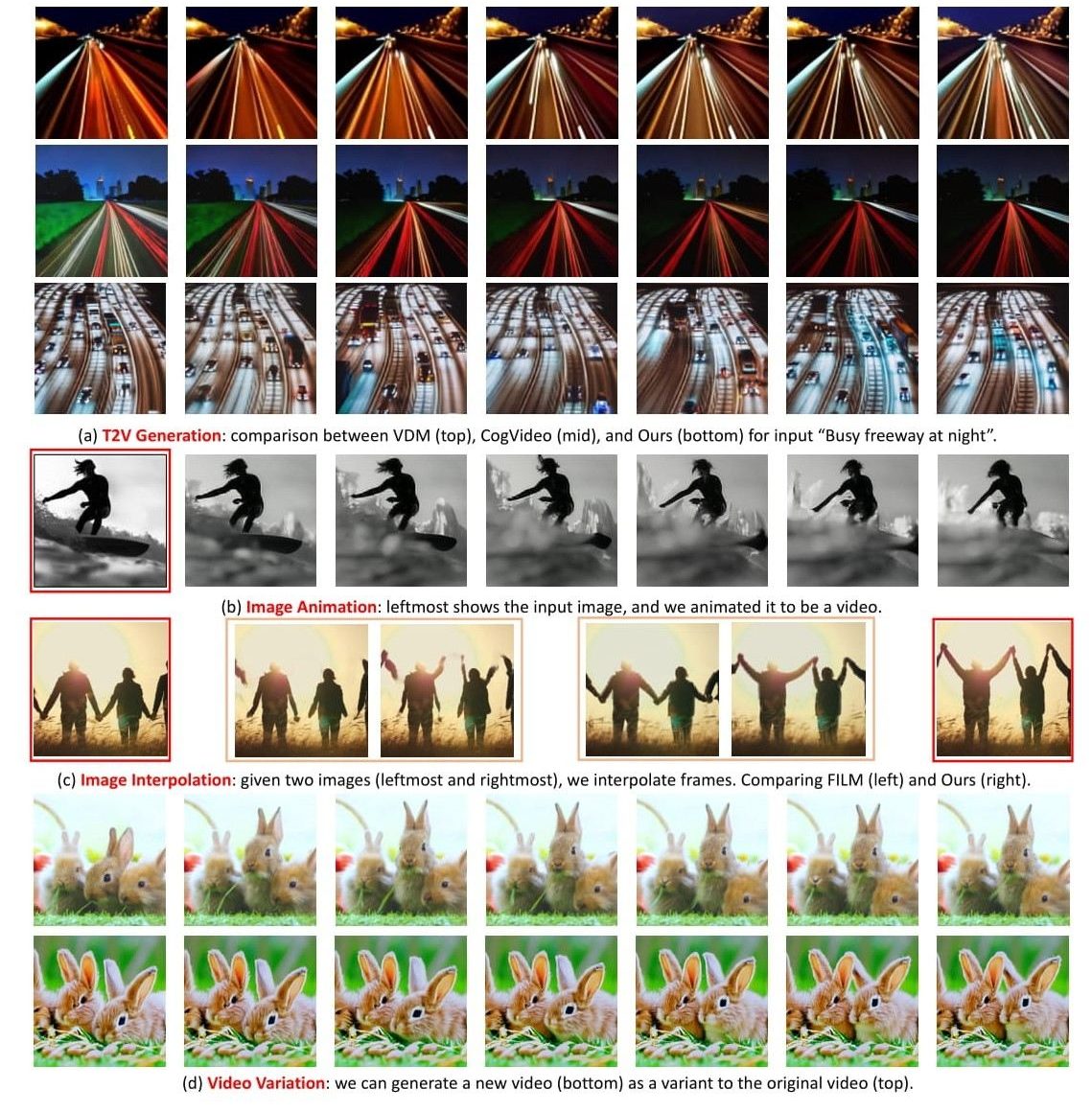
На данном этапе развития Make-A-Video позволяет производить видео продолжительностью до 5 секунд без аудио. Помимо текстовых команд, для генерирования видеоконтента можно использовать статические изображения. Кроме того, нейросеть позволяет создавать многочисленные вариации сочетания кадров на основе одного видео. По словам разработчиков из Meta, выходные данные генератора будут постепенно совершенствоваться. Для сравнения: всего несколько лет назад генераторы изображений производили картинки, в которых с большим трудом узнавались заданные объекты, а сегодня они способны синтезировать фотореалистичный контент, очень близко отражающий даже мельчайшие детали текстового описания. Хотя прогресс в улучшении качества синтезируемого видеоконтента будет более медленным, учитывая больший объём данных, подлежащих обработке, конечный результат в виде возможности создавать видео по простым текстовым командам послужит мотивацией для многих компаний и организаций привлечь как можно больше ресурсов для ускорения этого процесса.

По словам разработчиков, в текущем варианте модель имеет множество технических ограничений, помимо размытости объектов и искажения анимаций. К примеру, в видео с машущей рукой нейросеть пока не может определить направления её движений. Кроме того, Make-A-Video с большим трудом даются видео продолжительностью более 5 секунд, с несколькими сценами и/или событиями и в более высоком разрешении. Сейчас модель генерирует до 16 кадров видео с разрешением 64 × 64 пикселя, а затем другая ИИ-нейросеть увеличивает разрешение готового видео до 768 × 768 пикселей.
В Meta считают, что подобные ИИ-модели могут стать неоценимым инструментом для художников и создателей контента. Однако в то же время в компании признают, что, как и другие подобные проекты, Make-A-Video может оказаться средством дезинформации, пропаганды, мошенничества и даже преследования или шантажа. Кроме того, разработчики отметили, что обучение нейросети за счёт данных веб-скрейпинга делает её более склонной к отображению в генерируемом контенте социальных предрассудков. Потому в ходе развития подобных систем Deep Learning-инженеры также будут работать над методиками, которые позволят осуществлять более строгий контроль генерируемого контента, чтобы ограничить либо и вовсе предупредить их неправомерное использование.