Стремительное распространение генеративных ИИ-технологий не обошло стороной и образовательную сферу. В связи с этим многие преподаватели выразили обеспокоенность тем, что студенты злоупотребляют подобными программами для написания своих работ. Реакцией на подобные жалобы стало появление множества «детекторов ИИ-плагиата», которые должны идентифицировать тексты, написанные большими языковыми моделями вроде ChatGPT. Впрочем, многочисленные исследования показывают, что подобные инструменты лишь добавили головной боли как преподавателям, так и студентам из-за явной предвзятости к не-носителям английского языка.

Ни для кого не секрет, что среди студентов хватает желающих воспользоваться благами цивилизации, а точнее – активным развитием генеративных ИИ-программ для написания как рутинных домашних, так и полноценных научных работ. От этого не только страдает академическая честность, но также теряется смысл самого образования. В рамках борьбы со злоупотреблением ИИ-технологиями в сети стали появляться разнообразные инструменты для выявления авторства искусственного интеллекта и сопряжённого с его деятельностью плагиата.

Команда учёных из Стэнфордского университета во главе с доцентом Джеймсом Цзоу опубликовала исследование, в рамках которого эксперты проанализировали результаты оценки эссе для TOEFL – теста на знание английского языка как иностранного – написанного 91 не-носителем английского языка, семью различными программами-детекторами ИИ. В качестве контрольной группы выступали эссе носителей языка. Более половины эссе, написанных не-носителями языка, алгоритмы идентифицировали как «сгенерированный ИИ контент», в то время как все работы из контрольной группы были признаны оригинальными. По словам Цзоу, такие итоги исследования заставили его команду задуматься о том, насколько в принципе эффективны детекторы ИИ-плагиата, если реальный ИИ-контент может их обойти, а оригинальные сочинения, написанные человеком, настолько часто классифицируются ошибочно.
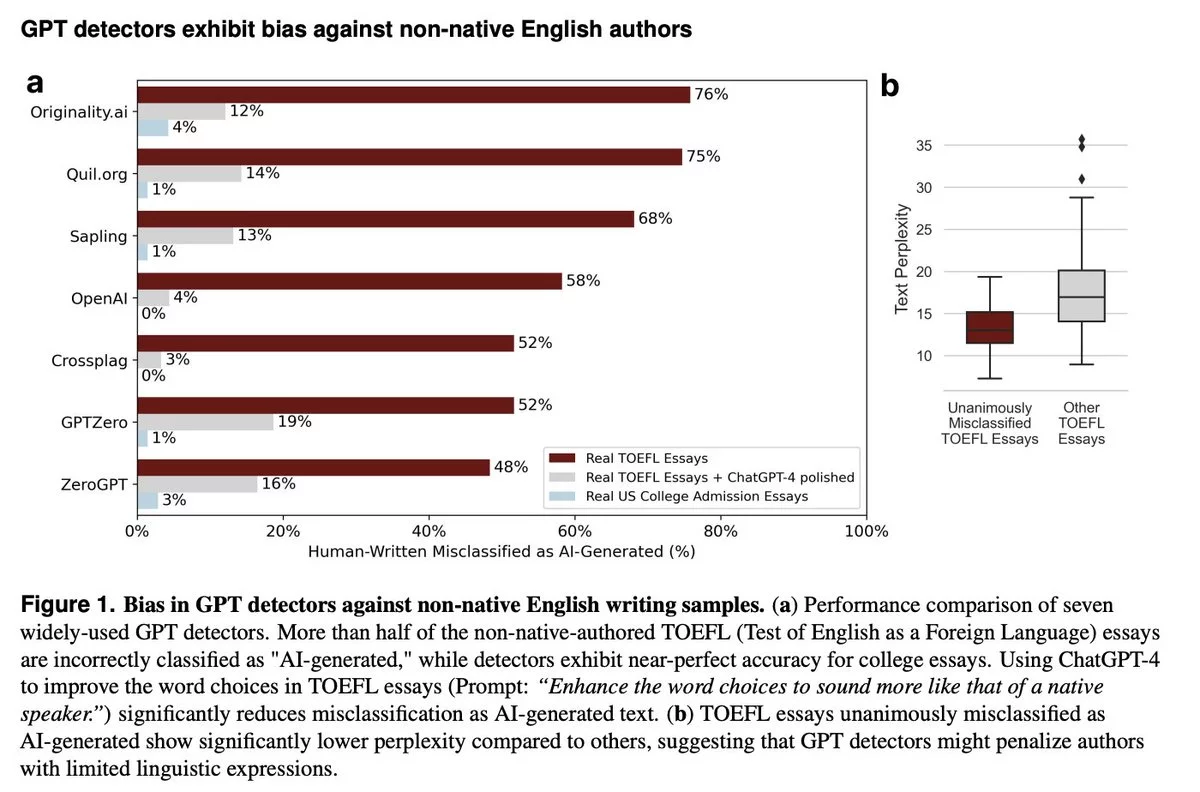
По мнению исследователей, главная проблема ИИ-детекторов заключается в алгоритме «затруднения текста», который описывает процентное содержание нестандартной лексики в письменной работе. Генеративные программы зачастую обучены симулировать низкую степень «затруднения текста», имитируя простейшие речевые паттерны. Таким образом, если человек, не являясь носителем языка, выбирает более простые и распространённые слова для построения своей письменной работы, детектор может «опознать» в его тексте следы работы ИИ-программы. Если же автор использует больше сложных и высокопарных слов и выражений, алгоритм с большей долей вероятности классифицирует его работу как оригинальную.

В рамках эксперимента по определению пределов параметров ИИ-детекторов Цзоу пошёл ещё дальше. Так, его команда использовала ChatGPT для «улучшения» эссе, написанных не-носителями английского языка, и направила «усложнённые» тексты на повторную проверку. На этот раз все 7 программ идентифицировали гораздо большее количество работ как «написанные человеком». Вероятно, аналогичные реазультаты можно повторить и в отношении носителей и не-носителей других языков. Другими словами, ИИ-контент пока далёк от идеала, однако то же самое можно сказать и об ИИ-детекторах: в настоящий момент их нельзя назвать надёжным инструментом для идентификации попыток нарушения принципов академической честности.