Представители некоммерческой компании Open AI, которая занимается разработкой технологий на базе искусственного интеллекта, приняли решение опубликовать только пробную модель GPT-2. Причиной тому стали опасения о возможности злоумышленного применения технологии генерирования текстов.

Open AI осуществляет свою деятельность при поддержке гигантов силиконовой долины: Илона Маска, Рида Хоффмана, Сэма Альтмана, Грега Брокмана, Джессики Ливинстон и Питера Тиля. GPT-2 является логическим продолжением GPT – языковой модели, способной генерировать логичные и последовательные тексты на основе текстов-образцов. Модель GPT-2 гораздо более совершенна, она обучена на основе 8 миллионов веб-страниц, общий объём которых превышает 40 Гб. Благодаря разнообразию исходных текстов модель может не только генерировать реалистичные тексты, но и выполнять различные задачи по обработке естественного языка.


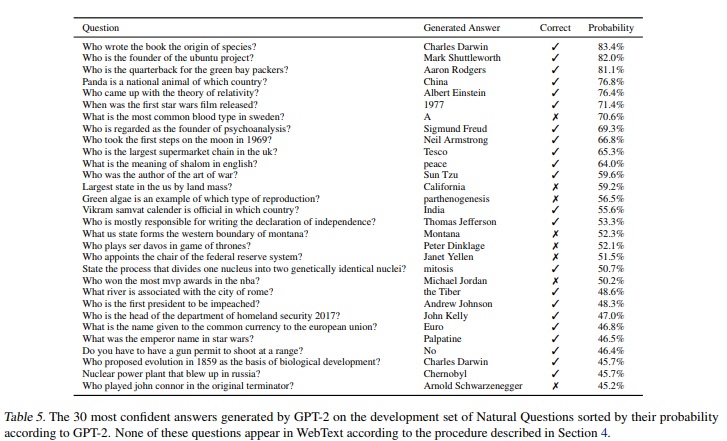
GPT-2 формулирует тексты в ответ на произвольные запросы, которые могут выглядеть как вопросы или утверждения и состоят из одного-двух предложений. Языковая модель как хамелеон подстраивается под заданный стиль и содержание, чтобы сгенерировать связное продолжение. Судя по представленным в сети примерам, GPT-2 с лёгкостью создаёт тексты на актуальные темы, которые широко представлены в сети. Успех языковой модели зависит от того, насколько хорошо система ориентируется в контексте. По наблюдениям исследователей, в 50% случаев GPT-2 сможет сформулировать связный текст, но иногда система сталкивается с трудностями. В результате встречаются повторения слов, неестественные отклонения от темы или ошибки в описании реалий нашего мира, например, «fires happening under water». Также затруднения вызывали узкоспециализированные темы, например, техника или эзотерика. Более точная регулировка параметров языковой модели в будущем гарантирует создание более реалистичных и связных текстов, потому изучение слабостей языковой модели и её совершенствование является перспективной исследовательской областью.

Языковая модель показала отличные результаты в решении предметно-ориентированных задач по обработке естественного языка. GPT-2 удалось превзойти рекордные показатели специализированных программ в режиме «zero-shot», то есть модель компании Open AI решала задания за счёт имеющегося объёма «знаний» без подготовки к конкретным заданиям. Особые успехи GPT-2 показала в задачах Winograd Schema Challenge (70,7% правильных ответов), LAMBADA (63,24%) и Children’s Book Test (93,3%).

В заданиях, направленных на восприятие, анализ и резюмирование текстов, модель GPT-2 опиралась на базу данных CoQA (Conversational Question Answering). То же касается и ответов на вопросы в тесте на общую эрудицию. CoQA содержит более 127 тысяч вопросов и ответов, извлечённых из диалогов на различные темы. На данном этапе удалось получить правильные ответы на вопросы в 63,1% случаев, но исследователи уверены, что по мере изучения новых данных показатели эффективности модели в выполнении подобных заданий вырастут.
Ожидается, что в будущем системы, подобные GPT-2, будут использоваться в качестве ИИ-программ для редакции и перевода текстов, а также для совершенствования технологий распознавания речи. Как некоммерческая компания, Open AI всегда охотно делится своими достижениями в сфере изучения и разработки технологий, использующих искусственный интеллект. Однако результаты GPT-2 оказались настолько впечатляющими, что, во избежание использования языковой модели для создания фальшивых новостей, генерирования спама, фишинга и другого потенциально опасного контента, компания решила не публиковать развёрнутую информацию о модели и датасет для её обучения.

Представители компании Open AI призывают публику более скептически относиться к информации в свободном доступе в сети, поскольку в наши дни появляется всё больше возможностей синтезировать не только фальшивые новости, но и фото, видео- и аудиозаписи. Разработчики программ ИИ считают, что контроль деятельности подобных технологий должен производиться более систематизировано на государственном уровне, чтобы избежать провокаций и в то же время не препятствовать дальнейшему развитию систем ИИ.

С образцами созданных языковой моделью текстов Вы можете ознакомиться в блоге компании.