Некомерційна організація Arc Prize Foundation, заснована відомим дослідником технологій машинного навчання Франсуа Шолле, повідомила про створення нового тесту для вимірювання загального інтелекту провідних ШІ-моделей. Поки що жодна з них не впоралася з тестом ARC-AGI-2.

Тест ARC-AGI складається з низки завдань у стилі головоломок, в яких ШІ має ідентифікувати певні візуальні патерни в наборах різнокольорових фігур та використати ці закономірності для генерації правильної відповіді. Цей тест було створено таким чином, аби змусити штучний інтелект адаптуватися до розв’язання невідомих раніше задач. За словами Шолле, головна відмінність ARC-AGI-2 від першої версії тесту полягає у тому, що він виключає можливість використання грубої обчислювальної сили для швидкої перевірки всіх можливих варіантів задля пошуку єдиної правильної відповіді. Ця лазівка була серйозним недоліком ARC-AGI-1.

За версією Arc Prize Foundation, оновлена версія тесту є набагато кращим мірилом реального рівня загального інтелекту ШІ-моделей, що насамперед проявляється у їхній здатності опановувати нові знання та навички за межами даних з його тренувальної бази. У ньому також з’явилася нова метрика – ефективність. Тобто інтелект оцінюється не за вмінням розв’язання головоломок абияк та набором великої кількості балів, а за здатністю швидко розвивати нові навички та використовувати їх в незнайомому контексті. І нарешті, ARC-AGI-2 вимагає від ШІ вміння інтерпретувати патерни на льоту, а не покладатися на запам’ятовування даних, що могли б допомогти з ідентифікацією закономірностей.
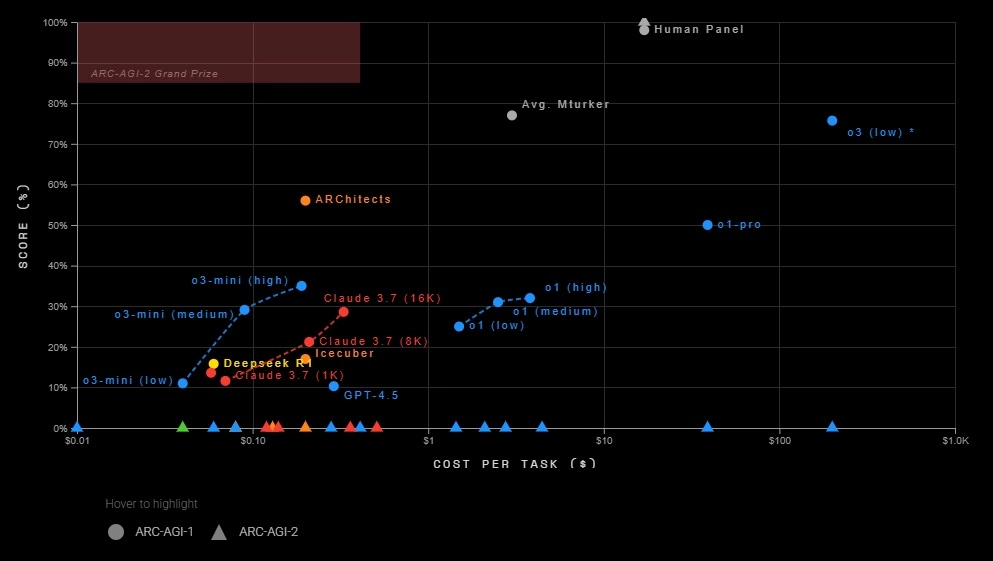
Навіть із певними лазівками ARC-AGI-1 була непереможною для ранніх ШІ-моделей протягом майже п’яти років, допоки OpenAI не випустила нову генеративну модель логічного міркування o3, яка перевершила всі інші моделі штучного інтелекту та у межах тесту не поступалася за продуктивністю людині. Так, o3 впоралася з тестом на 75,7%, але цей здобуток виявився недешевим з погляду витрат на обчислювальну потужність – до $200 на кожне завдання. Втім, навіть такі витрати не допомогли o3 набрати прохідний бал в ARC-AGI-2, хоч ця модель впоралася з тестом значно краще за інші моделі – на 4%. Для порівняння: моделі міркування o1-pro і DeepSeek R1 набрали від 1% до 1,3%, а потужні, проте не здатні до логічного міркування моделі на кшталт GPT-4.5, Claude 3.7 Sonnet чи Gemini 2.0 Flash ледве дібрали 1%. Водночас Arc Prize Foundation також провела випробування того ж тесту за участі понад 400 людей: у середному піддослідні правильно відповіли на 60% завдань.
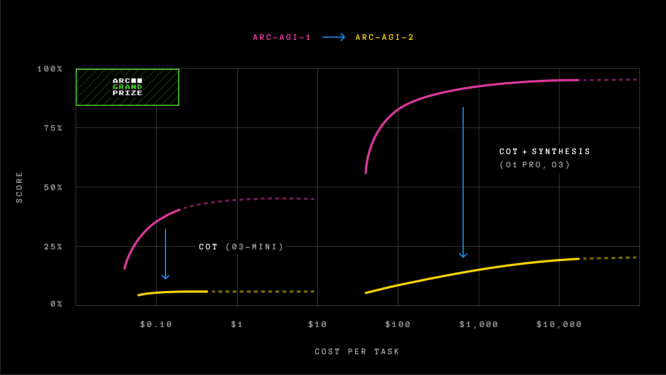
Окрім нового тесту, Arc Prize Foundation також оголосила про змагання Arc Prize 2025 із грошовими призами. Головною вимогою конкурсу є досягнення результату у 85% в новому тесті із витратами не більше за $0,42 на кожне завдання. Переможців буде визначено у грудні 2025 року.