Исследователи из Массачусетского Технологического Института разработали программу, способную воссоздать внешность человека на основе небольшой аудиозаписи. Новое приложение получило название «Speech2Face». С докладом о ходе работ и результатах исследования можно ознакомиться в крупнейшем онлайн архиве электронных публикаций и научных статей arXiv.org.

Speech2Face представляет собой стандартную генеративно-состязательную нейросеть, которую обучили на основе базы данных AVSpeech. Это база состоит из миллионов 6-секундных фрагментов видео с YouTube, на которых запечатлены сотни тысяч людей. По задумке авторов, одной из ключевых целей исследования было изучение взаимосвязей между внешностью человека и его манерой речи, голосом, интонациями и т. п. Изучив предоставленные видео-сегменты, нейросеть сформировала ряд корреляций между голосом говорящего и его лицом. В частности, нейросеть сумела найти определённые закономерности между голосом и черепно-лицевыми структурами, например, строением носа, челюсти, губ и т. д. Кроме того, алгоритм Speech2Face может достаточно уверенно определять возраст (с точностью до 10 лет) и пол говорящего.
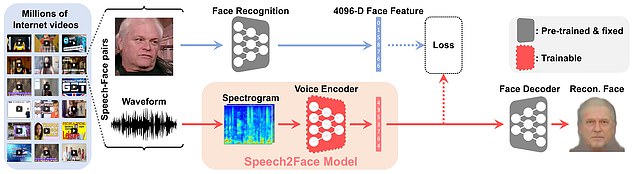

Исследователи вовсе не стремились научить Speech2Face точно воссоздавать облик человека по его речи. Пока что намерения учёных ограничиваются отображением основных особенностей внешности людей. В большинстве случаев нейросеть достаточно неплохо восстанавливает черты лица людей на основе их голоса, однако порой случаются и ошибки. Работа алгоритма во многом зависит от таких факторов как качество аудиозаписи, тон голоса, язык, акцент и т. п. Иногда особенности речи человека совершенно не совпадают с его обликом, что приводит к нестыковкам в работе алгоритма. Например, в ответ на запись мальчика с высоким голосом нейросеть воссоздавала лицо молодой девушки.

Особый диссонанс у Speech2Face вызывало противоречие языка, на котором говорил человек, и его этнической принадлежности. Когда программа получила два аудиоклипа с записью разговора одного и того же мужчины на английском и китайском языке, в первом случае она сгенерировала лицо белого мужчины, а во втором – азиата.

В современном мире практически любые новости, связанные с искусственным интеллектом, вызывают шквал как позитивных, так и негативных реакций. В случае с Speech2Face недовольство публики вызвало использование видео с YouTube для обучения нейросети. Некоторые люди даже обвиняли исследователей в нарушении неприкосновенности частной информации. На подобные обвинения учёные ответили, что система создаёт усреднённые образы, по которым определить личность говорящего практически невозможно.

Тем временем специалисты не отрицают появления такой возможности уже в ближайшем будущем, так как подобная технология имеет большие перспективы в самых разнообразных сферах. В первую очередь алгоритм воссоздания внешности по голосу человека может оказаться полезным разработчикам видеоигр, программ для визуализации аудиозвонков, мессенджеров и т. п. В таком случае изображение может как просто служить более индивидуализированным виртуальным аватаром пользователя, так и помогать идентифицировать мошенников или телефонных хулиганов.
