Уверены, Вам приходилось видеть фильмы и сериалы, в которых протагонист просит увеличить и улучшить изображение, полученное со случайной камеры наблюдения. В такие моменты с нажатием пары клавиш вместо размытых и едва различимых пятен на мониторе появляются чёткие снимки, раскрывающие личность преступника, автомобильные номера и прочие ключевые для сюжета детали. Корпорация Google представила новейшие ИИ-движки, основывающиеся на диффузионных моделях, способные провернуть аналогичный трюк.
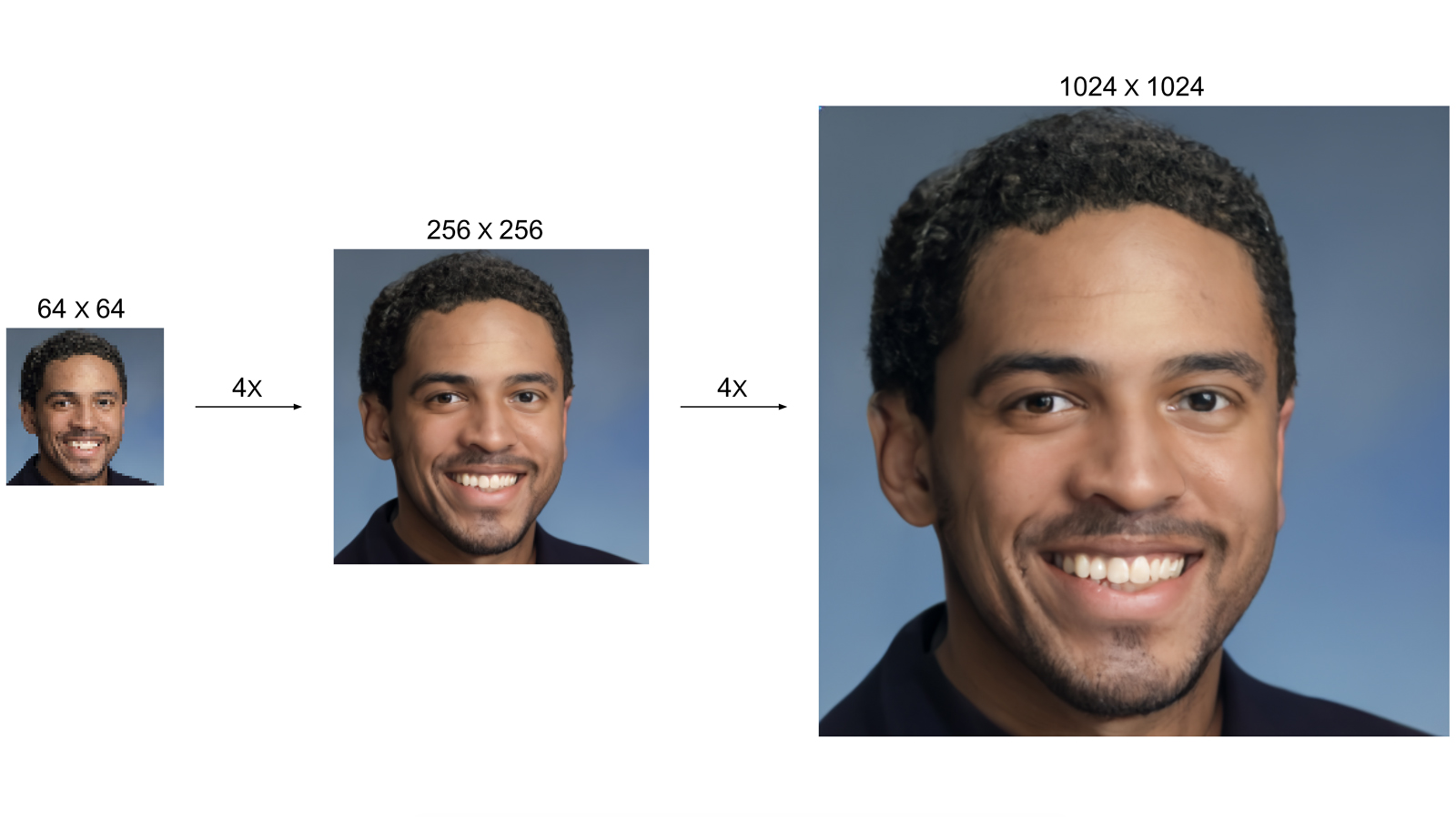
По словам специалистов Google, искусственному интеллекту довольно трудно «увеличить и улучшить» фотографию низкого качества. Дело в том, что нейросети приходится дополнять изображение деталями, которые не запечатлела камера, руководствуясь сторонними подсказками, полученными из других похожих снимков. Для реализации суперразрешения изображения эксперты Google разработали собственную технику синтеза изображений, которая делает маленькое пикселизированное фото большим, чётким и качественным. Результат не всегда в полной мере соответствует оригиналу, однако его реалистичность, как правило, достаточно убедительна для человеческих глаз.



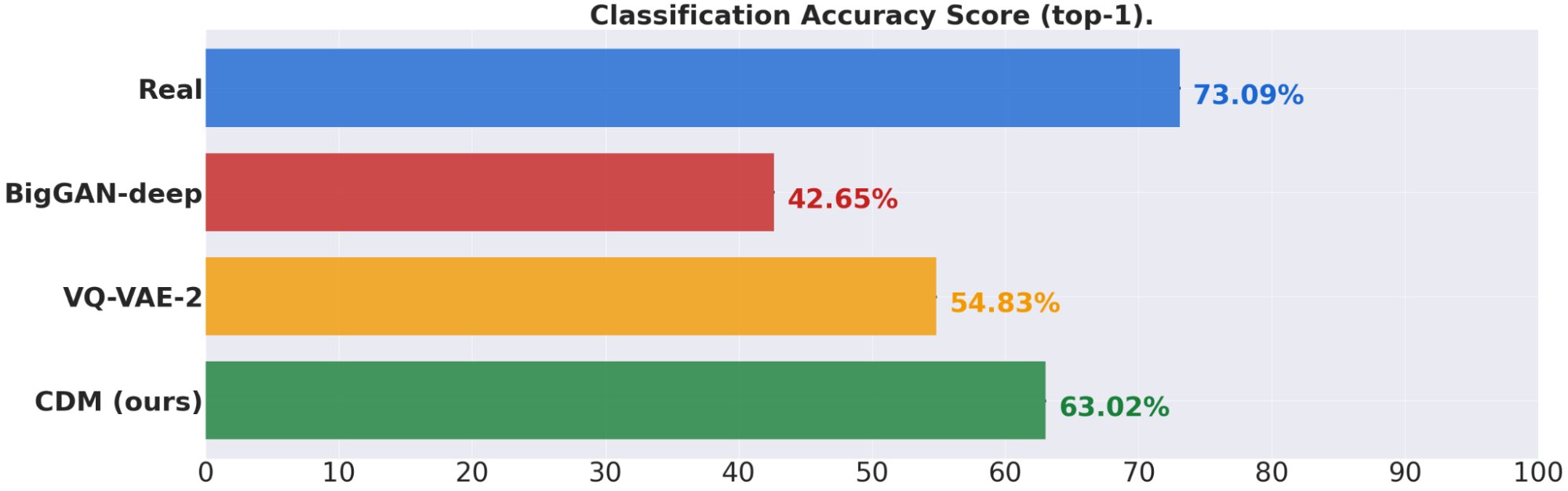
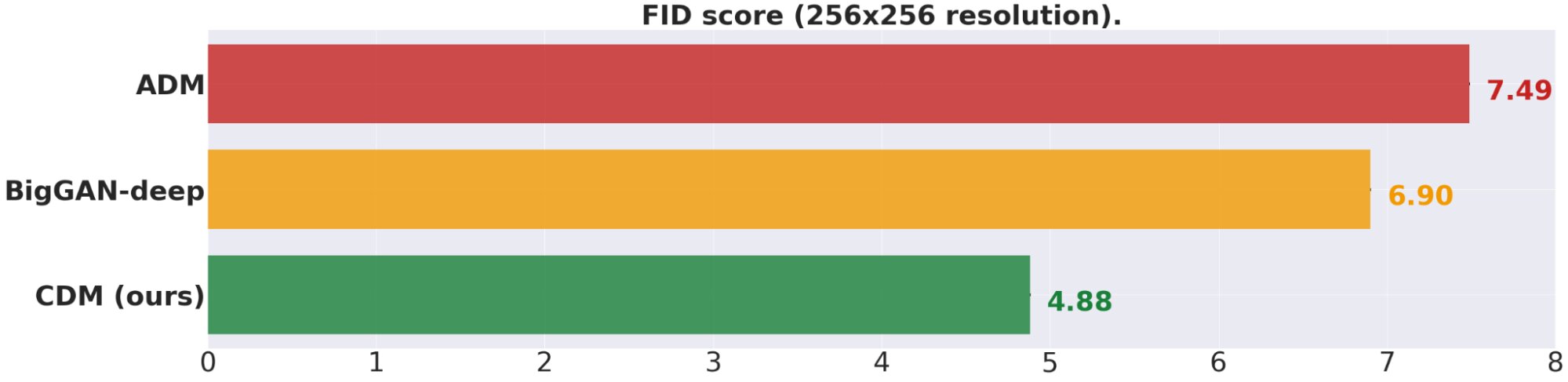
Второй алгоритм Cascaded Diffusion Models или CDM представляет собой многоуровневую систему из нескольких диффузионных моделей, в том числе и SR3. CDM позволяет постепенно повышать разрешение исходного изображения до получения максимально доступного результата с наименьшей потерей качества. Алгоритм, совмещающий в себе сразу нескольких моделей суперразрешения изображений, значительно превосходит по эффективности другие альтернативные методы увеличения разрешения фотографий. Не в последнюю очередь превосходство CDM обусловлено использованием в качестве тренировочной базы ресурса ImageNet, который нередко служит ключевым источником изображений для обучения систем визуального распознавания.


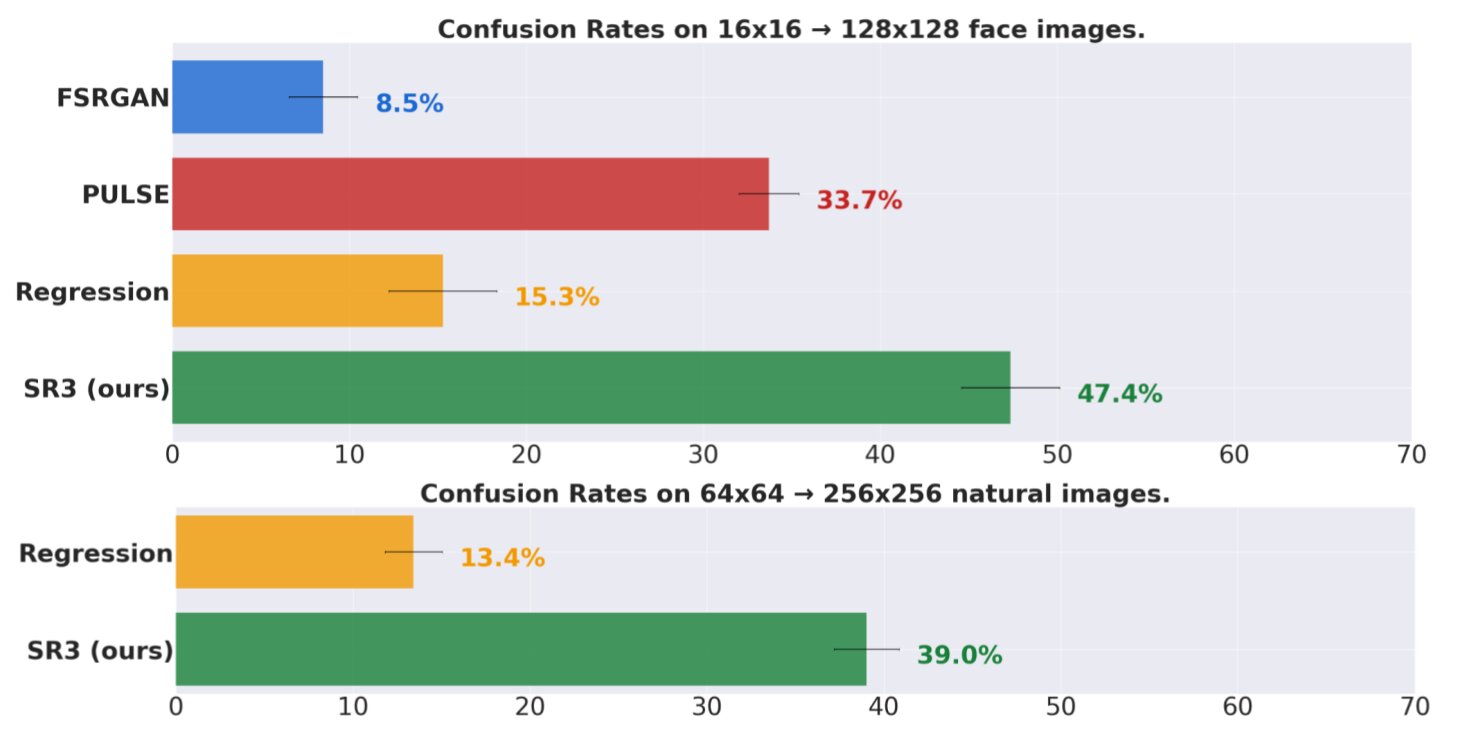
Представители Google сообщают о весьма многообещающих результатах совместной работы алгоритмов SR3 и CDM. В рамках испытаний моделей примерно в 50% случаев 50 добровольцев принимали сгенерированные ими изображения за реальные фотографии. Впрочем, эксперты подчеркнули, что синтезированные изображения являются не полноценными копиями оригинальных снимков, но результатом тщательного вычисления вероятностей. Специалисты Google заявили, что алгоритмы на базе диффузионных моделей производят более правдоподобные изображения, чем альтернативные ИИ-программы, включая алгоритмы GAN, которые основываются на комбинации генеративных и дискриминативных моделей.
Пока что Google не предоставила информации о возможностях и сроках коммерческой реализации подобных ИИ-движков. К слову, эксперты компании считают, что будущее диффузионных моделей не ограничено операциями по улучшению качества изображений. Учёные предполагают, что данные алгоритмы и их вариации найдут применение в различных отраслях науки и техники, полагающихся на инструменты вероятностного моделирования.
Источник: High Fidelity Image Generation Using Diffusion Models