Компанія Google представила Aeneas – новий інструмент на основі штучного інтелекту, який допоможе історикам реконструювати та розшифрувати вміст стародавніх римських написів.

Новий інструмент штучного інтелекту, розроблений Google DeepMind, допомагає вченим заповнювати прогалини в стародавніх написах та аналізувати вміст історичних текстових артефактів. Aeneas працює, генеруючи обґрунтовані припущення на основі контексту та подібних написів. Назва інструменту походить від імені персонажа античної міфології Енея, одного з найславетніших героїв Трої. Вчені спираються на стародавні написи, щоб поглибити наше розуміння римського світу, але, на жаль, їх не завжди легко розшифрувати. Для того, аби розібратися з новими письмовими артефактами, історики часто шукають «паралелі» – інші тексти, які мають схоже формулювання, синтаксис та походження.

Новий ШІ-інструмент Google було створено за прикладом аналогічного проєкту для грецьких написів Ithaca, щоб пришвидшити цей процес. Згідно з офіційним повідомленням Google DeepMind, Aeneas за лічені секунди аналізує тисячі латинських написів, знаходячи текстові та контекстуальні паралелі. Базуючись на висновках моделі, вчені можуть обирати, як саме інтерпретувати досліджуваний письмовий артефакт та його вміст. За даними дослідження ШІ-моделі, опублікованої в журналі Nature, щороку археологи виявляють приблизно 1500 стародавніх римських написів. На думку історика Теї Зоммершельд з Ноттінгемського університету, яка брала участь у створенні моделі, найцікавішим аспектом таких знахідок є усвідомлення того, що звичайні люди з різних соціальних прошарків колись доклали своєї руки до їхнього створення. Це та сама реальна історія, яку написали не лише переможці, але й учасники.
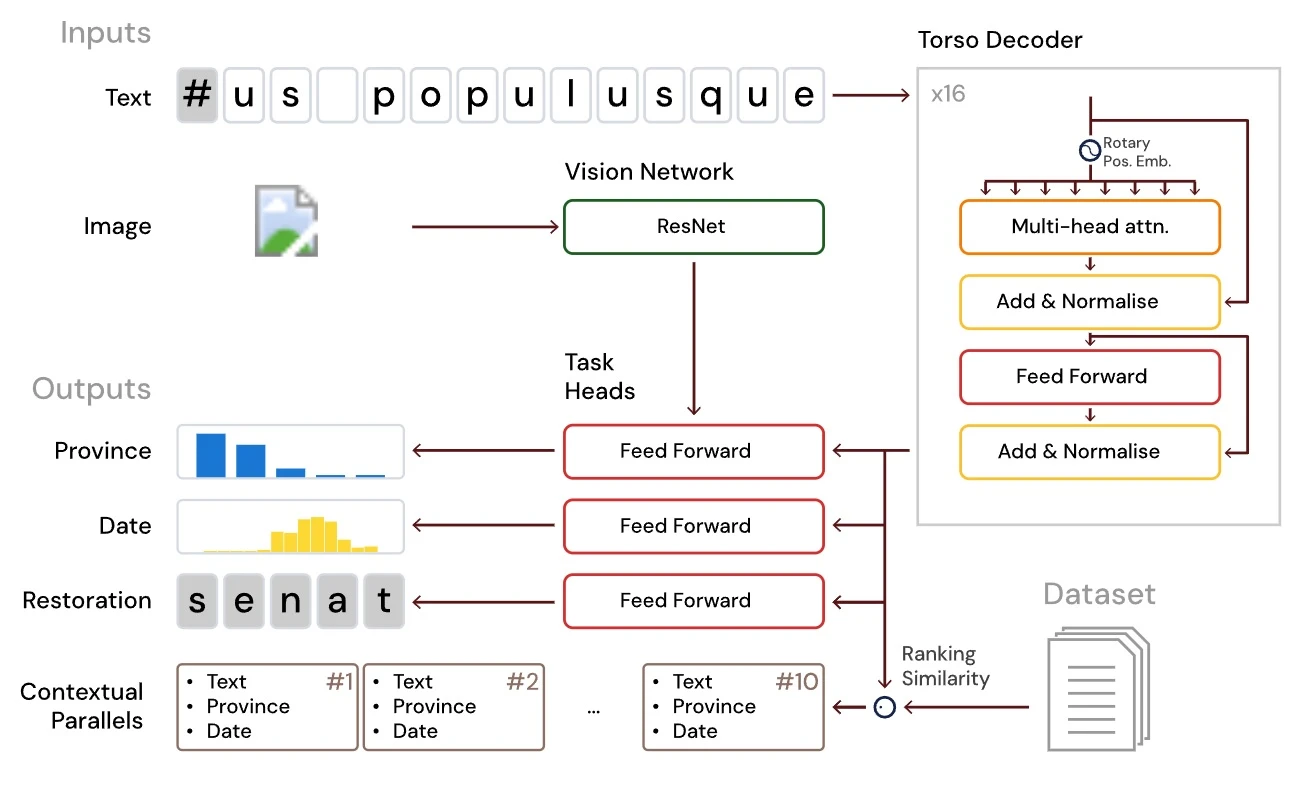
Для того, щоб Aeneas міг допомогти вченим реконструювати та розшифровувати ці написи, команда Google DeepMind використала низку найбільших у світі баз даних латинської епіграфіки, як-от Epigraphic Database Roma, Epigraphic Database Heidelberg та Epigraphik-Datenbank Clauss-Slaby. Команду Google очолив дослідник штучного інтелекту Янніс Ассаїл, під керівництвом якого вона об’єднала весь матеріал до єдиної тренувальної бази з понад 176 000 написів, які походять з різних куточків Римської імперії. Коли штучний інтелект отримує новий напис, він генерує перелік паралелей за контекстом та походженням, а потім використовує їх, щоб припустити, чого може не вистачати в тексті. Аналіз ефективності моделі демонструє: якщо розмір прогалини обмежений не більш як 10 символами, то точність реконструкції напису сягає 73%. Якщо ж її обсяг невідомий, то точність Aeneas падає до 58%. Штучний інтелект може із точністю до 72% приписати походження тексту до однієї з 62 римських провінцій, а також встановити дату його створення з відхиленням до 13 років.
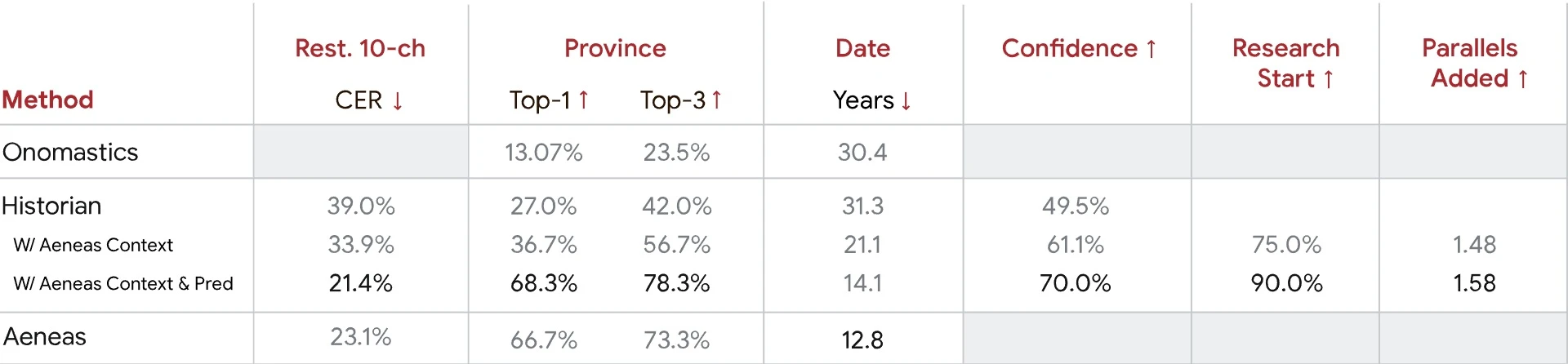
Під час одного з тестів модель проаналізував один з найвідоміших римських написів: Res Gestae Divi Augusti, коротку автобіографію імператора Августа. Точний час створення тексту залишається предметом дискусій вже протягом багатьох років. Замість загального діапазону дат Aeneas навів періоди, на які припадають піки ймовірності: один між 10 і 20 роками н. е., а другий – між 10 і 1 роком до н. е. Висновки штучного інтелекту узгоджуються з основними науковими гіпотезами, що стало великим шоком для творців. На думку дослідників, ця модель має трансформаційний потенціал. Найзмістовніші прориви в галузі історії Стародавнього Риму зазвичай спиралися на пам’ять свідків, суб’єктивні судження та здогадки окремих постатей, підкріплених інтерпретаціями історичних артефактів. Поява Aeneas відкриває нові горизонти для поглиблення нашого розуміння історії імперії. Інтерактивна версія моделі доступна безкоштовно на сайті predictingthepast.com, а код і база даних є у відкритому доступі на платформі GitHub.