Даже при использовании качественных слуховых аппаратов людям с нарушениями слуха может быть сложно выделять отдельные голоса из фонового шума. Инновационная система SpeakerBeam, разработанная японскими учёными из компании NTT Corporation, может стать эффективным решением благодаря автоматическому распознаванию и усилению голосов выбранных людей при помощи ИИ.

В середине прошлого века учёные идентифицировали так называемый «эффект коктейльной вечеринки», который описывает способность человека выхватывать релевантные сигналы – визуальные или акустические, будучи окружённым обширным потоком информации (фоновым шумом) за счёт селективного внимания. Для людей с нарушениями слуха, которые используют слуховые аппараты, эта задача многократно усложняется, поскольку подобные устройства, как правило, усиливают все звуковые сигналы в пределах определённого радиуса. Как следствие, голос собеседника зачастую теряется среди голосов окружающих и посторонних звуков. Сегодня на рынке представлены различные вариации технологий, которые можно интегрировать в традиционные слуховые аппараты и использовать для изоляции и усиления голоса собеседника, который находится непосредственно перед пользователем. Подобные системы, бесспорно, актуальны и эффективны, однако они имеют существенные ограничения.
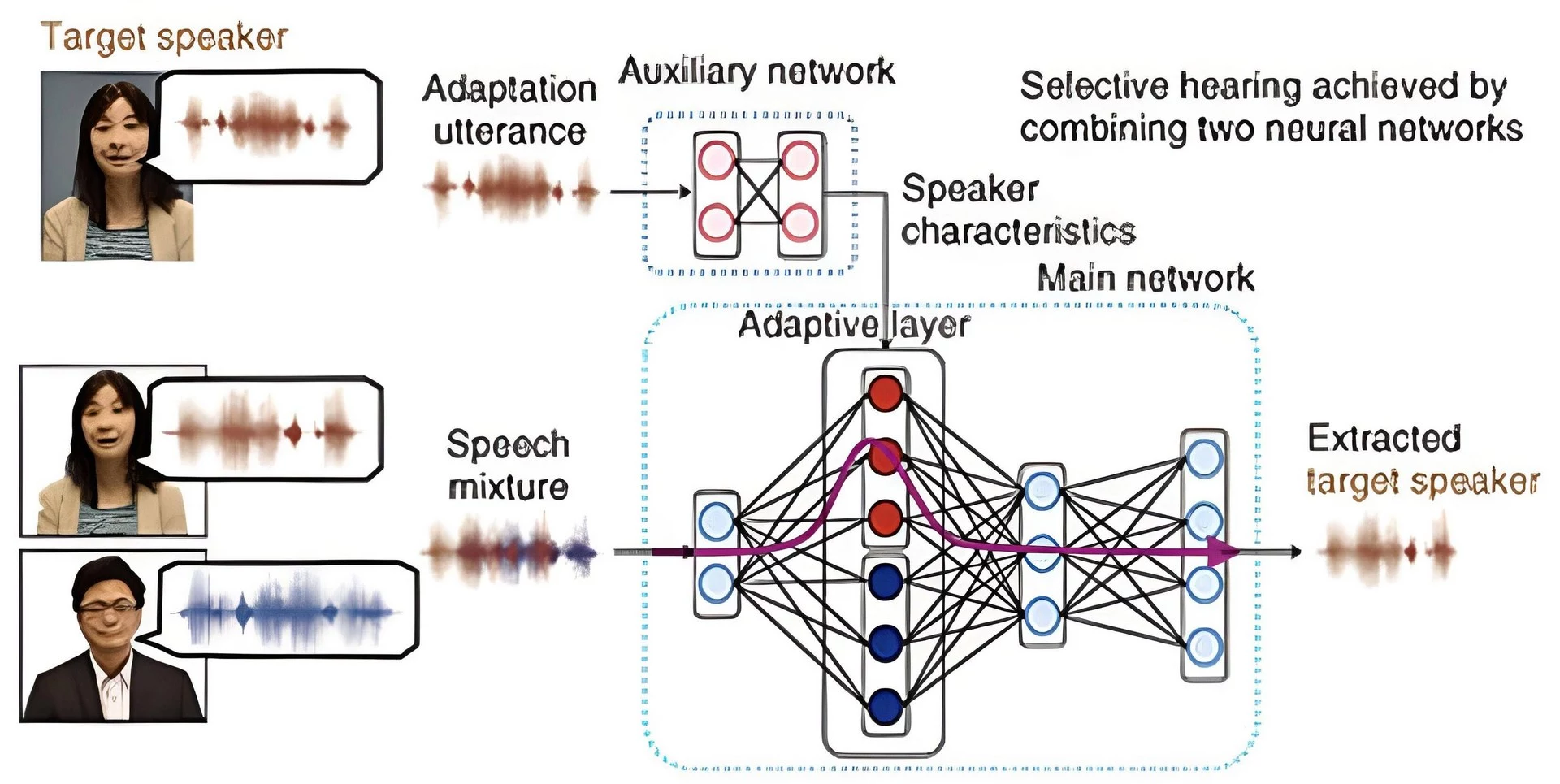
Эксперты из NTT Corporation решили разработать альтернативу в виде SpeakerBeam – системы, способной идентифицировать и усиливать выбранные голоса вне зависимости от их расположения по отношению к пользователю. Подобный функционал реализован за счёт сочетания двух нейросетей. Для обучения первой нейросети системы необходим 10-секундный отрывок речи собеседника – так называемое «адаптационное произнесение». С его помощью ИИ выделяет ряд параметров, индивидуальных для выбранного голоса. Затем в условиях «коктейльной вечеринки» вторая нейросеть использует эти особенности, чтобы выделить голос собеседника среди фонового шума и голосов других людей и усилить его. И самое главное – SpeakerBeam продолжает усиливать только выбранный голос, даже если его обладатель не находится непосредственно перед лицом обладателя слухового аппарата.