Штучний інтелект приніс суттєві зміни до професійного та навіть особистого життя багатьох людей. До 52% дорослих щоденно користуються великими мовними моделями (LLM) переважно у формі чат-ботів на кшталт ChatGPT. У новому дослідженні вчені детально описали величезний екологічний тягар, пов’язаний з популярністю ШІ-систем, що змушує зайвий раз замислитись про необхідність використання чат-ботів та різні підходи до взаємодії з ними.
Дослідники з Мюнхенської вищої школи прикладних наук проаналізували 14 різних великих мовних моделей (LLM), взявши за еталон їхні відповіді на 1000 ідентичних питань. У таких моделях текст формується шляхом передбачення токенів, які можуть представляти слова, морфеми або навіть поодинокі символи. Кількість згенерованих ШІ токенів можна перевести в обсяг викидів парникових газів. За словами авторів, вплив LLM на довкілля визначається їхнім підходом до міркування, і чим детальнішим та складнішим є цей процес, тим вищим є обсяг спожитої енергії та викидів вуглецю. Так, вчені виявили, що моделі, що використовують більш складний підхід до міркування, виробляють майже у 50 разів більше викидів CO2, ніж моделі, здатні надавати простіші та більш стислі відповіді. Відповідно, перші генерують більше токенів за «колег» із більш узуальною логікою мислення.

По суті, токени – це результат операцій обчислення (пошуку інформації, оцінки тощо), які потребують певної обчислювальної потужності: разом з нею зростає і екологічний слід моделі. У процесі тренування LLM «навчається», коригуючи параметри, які є числами всередині нейронної мережі. Саме ці параметри контролюють, як модель прогнозує один токен за іншим. Отже, модель з меншою кількістю параметрів вважається простішою: вона покладається на менший обсяг інформації, враховує менше так званих «ваг» (ідентифікаторів, які вказують ШІ, наскільки важливими є ті чи інші елементи даних) та генерує менше токенів, але її відповіді можуть бути менш точними. Водночас моделі з більшою кількістю параметрів та ваг зазвичай мають точніші відповіді – проте не завжди, іноді це призводить лише до більш багатослівних «галюцинацій».
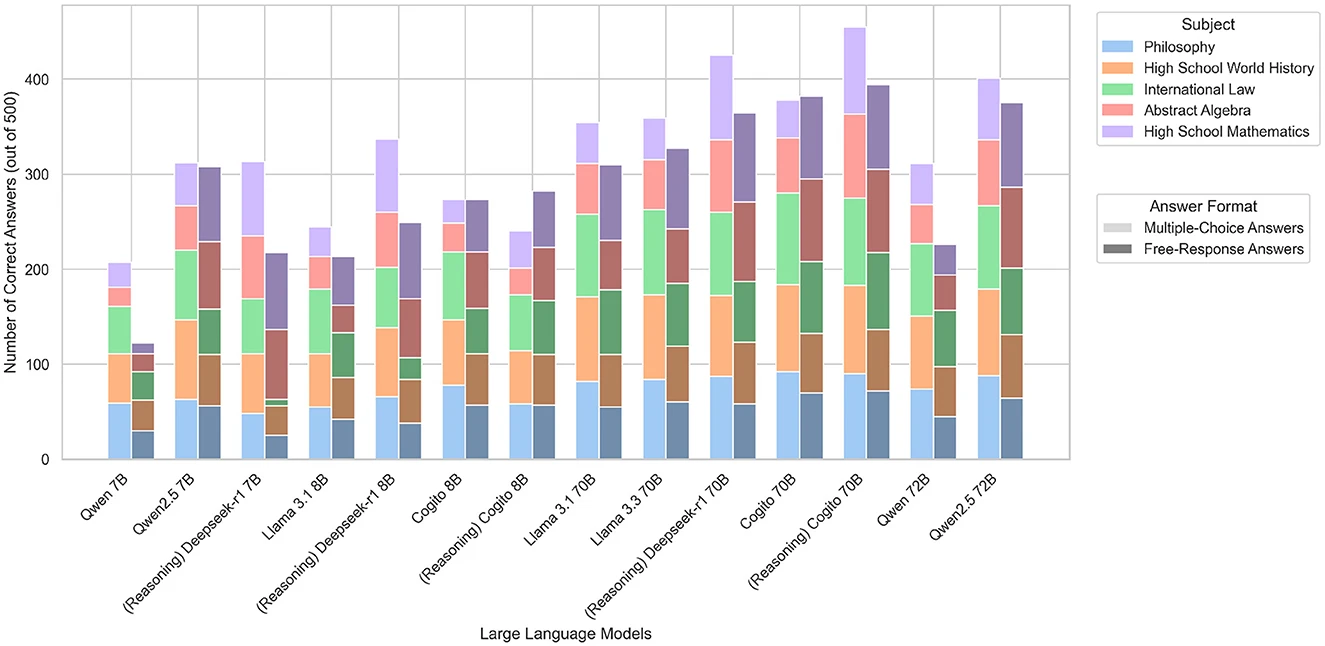 Під час аналізу вчені використовували комп’ютер з графічним процесором NVIDIA A100 та фреймворк Perun (який аналізує продуктивність LLM та необхідну потужність) для вимірювання споживання енергії, застосовуючи середній коефіцієнт викидів 480 г CO₂/кВт·год. Далі кожна з 14 моделей відповідала на 1000 питань в галузі філософії, світової історії, міжнародного права, абстрактної алгебри та шкільної математики. У тесті взяли участь текстові моделі та моделі міркувань від Meta, Alibaba, Deep Cognito та Deepseek. Аналіз комбінованих викидів парникових газів, точності відповідей та кількості згенерованих токенів для кожного з 1000 питань дозволив виявити чіткі тенденції між масштабом моделей, складністю їхнього міркування та їхнім впливом на довкілля.
Під час аналізу вчені використовували комп’ютер з графічним процесором NVIDIA A100 та фреймворк Perun (який аналізує продуктивність LLM та необхідну потужність) для вимірювання споживання енергії, застосовуючи середній коефіцієнт викидів 480 г CO₂/кВт·год. Далі кожна з 14 моделей відповідала на 1000 питань в галузі філософії, світової історії, міжнародного права, абстрактної алгебри та шкільної математики. У тесті взяли участь текстові моделі та моделі міркувань від Meta, Alibaba, Deep Cognito та Deepseek. Аналіз комбінованих викидів парникових газів, точності відповідей та кількості згенерованих токенів для кожного з 1000 питань дозволив виявити чіткі тенденції між масштабом моделей, складністю їхнього міркування та їхнім впливом на довкілля.
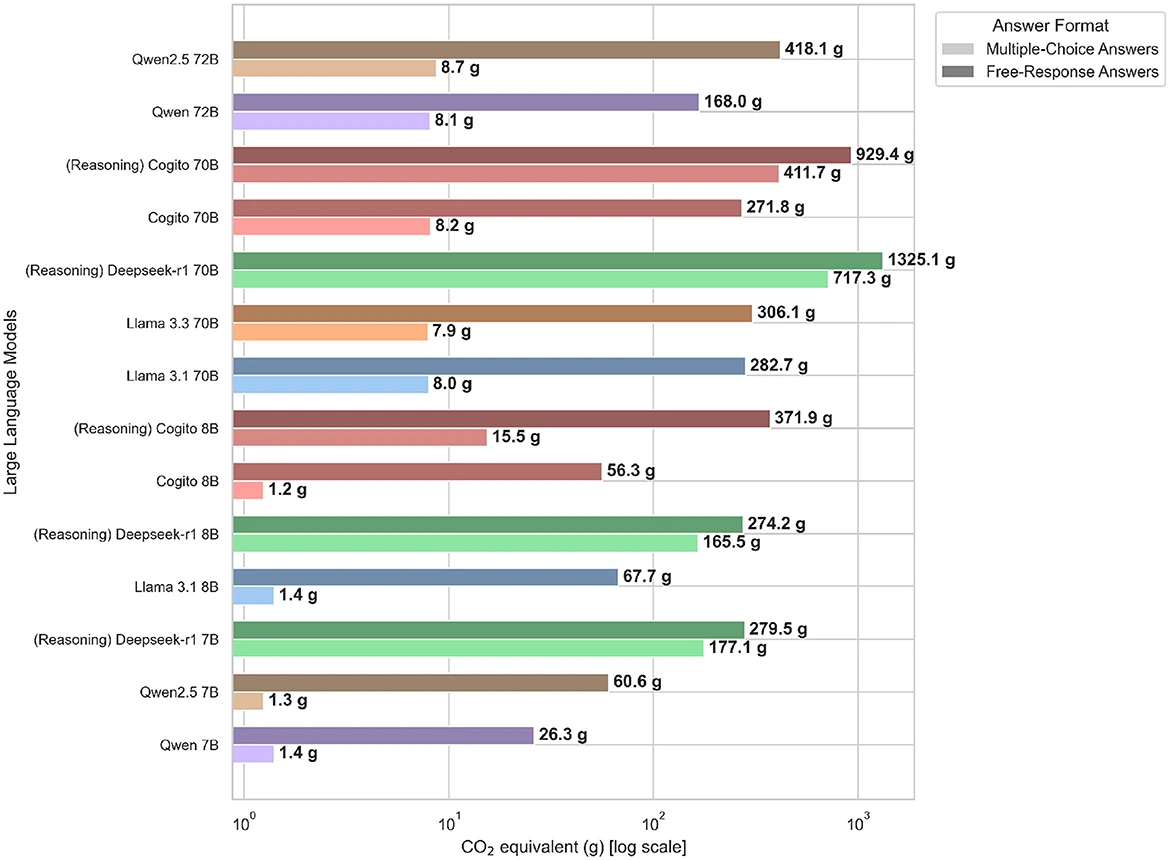 Вчені встановили, що складніші моделі, які імітують людські процеси міркування, створювали в середньому 543,5 токена на кожне питання вікторини, а суто текстові моделі в середньому генерували лише 37,7 токена для ідентичних запитань. Жодна з моделей, якій вдалося б утримати обсяг викидів меншим за 500 грамів CO2 (або еквівалентів), не впоралася з вікториною краще, ніж на 80%. Найточнішою виявилась модель Deep Cogito 70B (із 70 мільярдами параметрів), яка відповіла правильно на 84,9% запитань, але при цьому згенерувала втричі більше викидів за аналогічні LLM. Найменш енергоефективною показала себе модель Deepseek’s R1 70B, яка згенерувала 2042 г CO₂, що є еквівалентним викидам автомобіля з ДВЗ під час 15-км подорожі. Її точність досягла 78,9%. Менше за всіх викидів створила модель Qwen 7B від Alibaba – лише 27,7 г, але її відповіді були правильними лише у 31,9% випадків.
Вчені встановили, що складніші моделі, які імітують людські процеси міркування, створювали в середньому 543,5 токена на кожне питання вікторини, а суто текстові моделі в середньому генерували лише 37,7 токена для ідентичних запитань. Жодна з моделей, якій вдалося б утримати обсяг викидів меншим за 500 грамів CO2 (або еквівалентів), не впоралася з вікториною краще, ніж на 80%. Найточнішою виявилась модель Deep Cogito 70B (із 70 мільярдами параметрів), яка відповіла правильно на 84,9% запитань, але при цьому згенерувала втричі більше викидів за аналогічні LLM. Найменш енергоефективною показала себе модель Deepseek’s R1 70B, яка згенерувала 2042 г CO₂, що є еквівалентним викидам автомобіля з ДВЗ під час 15-км подорожі. Її точність досягла 78,9%. Менше за всіх викидів створила модель Qwen 7B від Alibaba – лише 27,7 г, але її відповіді були правильними лише у 31,9% випадків.
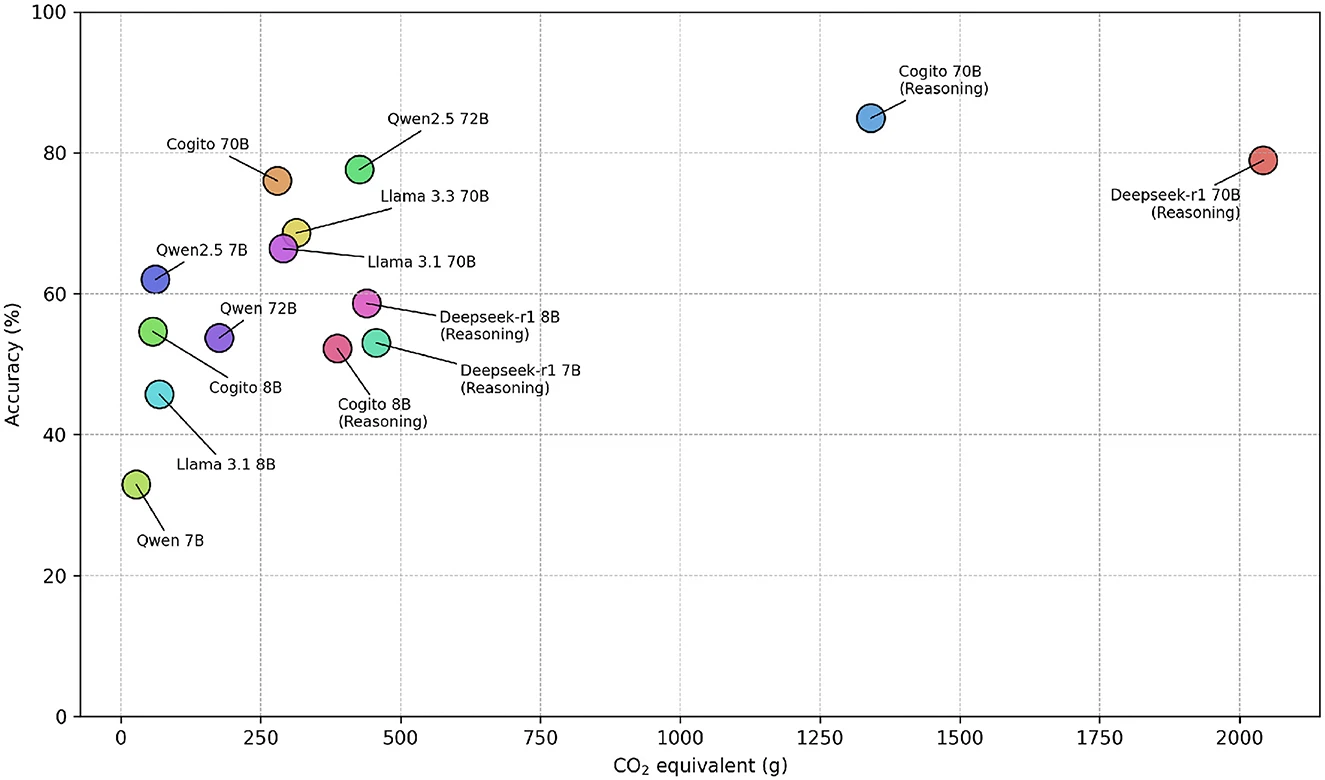 Дослідники також дізналися, що рівень споживання енергії змінюється залежно від теми. Так, питання з філософії та абстрактної алгебри вимагали більше обчислень, ніж вікторини з інших тематик. На жаль, в цьому випробуванні взяли участь виключно відкриті LLM, до яких має доступ широкий користувач. Вчені не розглянули найбільших гравців ринку штучного інтелекту на кшталт ChatGPT від OpenAI, Gemini від Google, Grok від X та Claude від Anthropic. Популярність штучного інтелекту в найрізноманітніших галузях людського життя означає, що в майбутньому LLM будуть інтегровані в нашу повсякденність ще сильніше. Тому людям варто вчитися працювати з ними якомога ефективніше, наприклад, обираючи ті чи інші моделі для завдань та запитань в різних сферах. Науковцям також необхідно докласти зусиль, аби зробити штучний інтелект більш енергоефективним.
Дослідники також дізналися, що рівень споживання енергії змінюється залежно від теми. Так, питання з філософії та абстрактної алгебри вимагали більше обчислень, ніж вікторини з інших тематик. На жаль, в цьому випробуванні взяли участь виключно відкриті LLM, до яких має доступ широкий користувач. Вчені не розглянули найбільших гравців ринку штучного інтелекту на кшталт ChatGPT від OpenAI, Gemini від Google, Grok від X та Claude від Anthropic. Популярність штучного інтелекту в найрізноманітніших галузях людського життя означає, що в майбутньому LLM будуть інтегровані в нашу повсякденність ще сильніше. Тому людям варто вчитися працювати з ними якомога ефективніше, наприклад, обираючи ті чи інші моделі для завдань та запитань в різних сферах. Науковцям також необхідно докласти зусиль, аби зробити штучний інтелект більш енергоефективним.
Джерело: Energy costs of communicating with AI / Maximilian Dauner, Gudrun Socher