Ранее в 2023 году в сети появились видео, созданные генеративным ИИ: результат был несколько странным и пугающим, однако алгоритм всё же выполнял поставленную задачу – строил анимации на основе текстового описания. Спустя считанные месяцы в рамках IEEE Conference NVIDIA представила собственную версию ИИ-видеогенератора, которая многократно превосходит предыдущие модели по качеству видео.
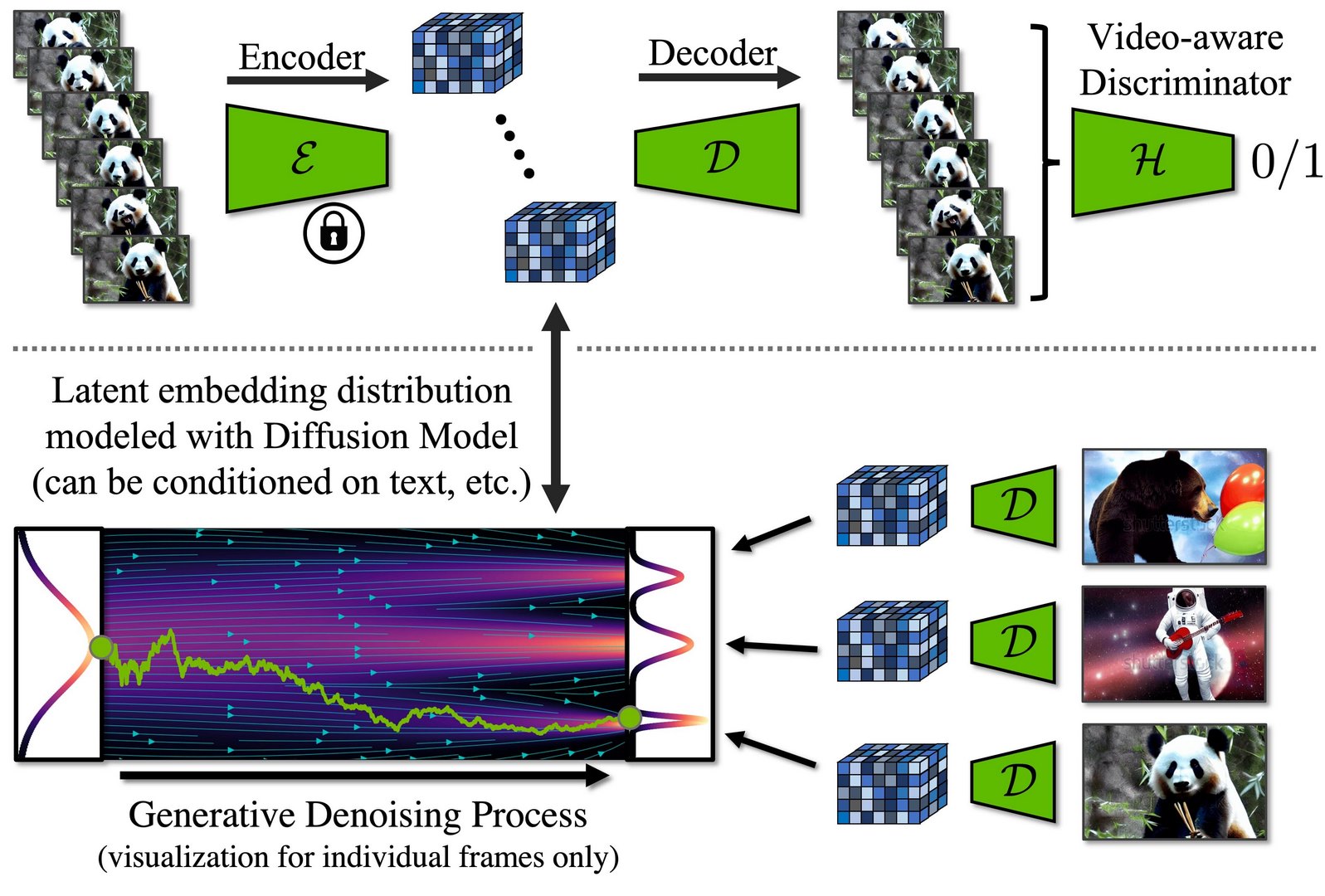
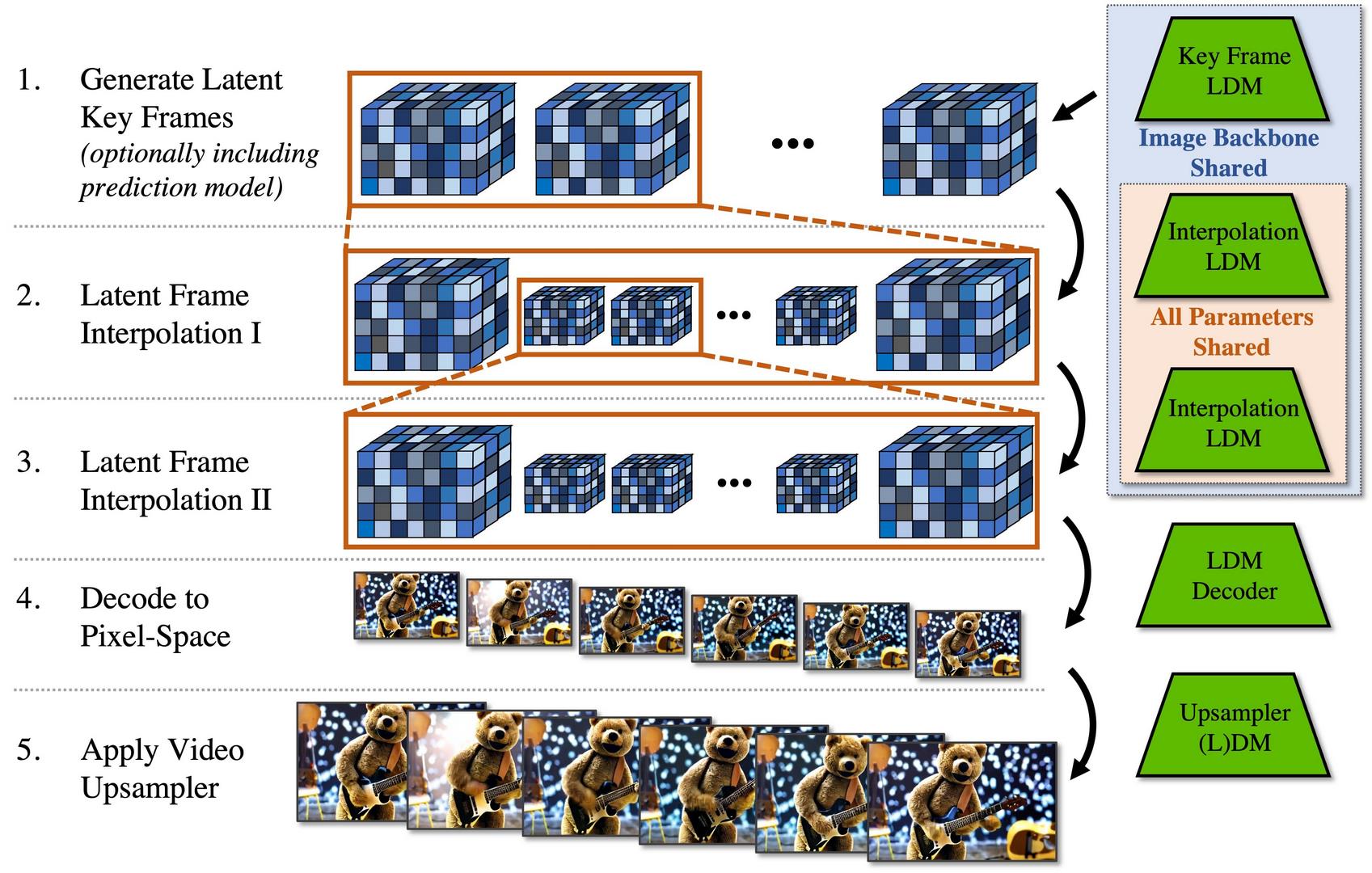
 По данным NVIDIA, в основе разработки лежит LDM – Latent Diffusion Model (латентная диффузионная модель), обученная сперва генерировать изображения по текстовым описаниям, а затем анимировать их, используя знания о движениях различных объектов из базы данных с тысячами обычных видео. Модель определяет время как дополнительное отслеживаемое измерение и рассчитывает, как будет меняться каждый фрагмент изображения за чётко обозначенный период. Таким образом, ИИ создаёт серию последовательных ключевых кадров, а затем использует дополнительную модель, чтобы интерполировать данные с ключевых кадров на промежуточные и создать ряд близких по качеству изображений.
По данным NVIDIA, в основе разработки лежит LDM – Latent Diffusion Model (латентная диффузионная модель), обученная сперва генерировать изображения по текстовым описаниям, а затем анимировать их, используя знания о движениях различных объектов из базы данных с тысячами обычных видео. Модель определяет время как дополнительное отслеживаемое измерение и рассчитывает, как будет меняться каждый фрагмент изображения за чётко обозначенный период. Таким образом, ИИ создаёт серию последовательных ключевых кадров, а затем использует дополнительную модель, чтобы интерполировать данные с ключевых кадров на промежуточные и создать ряд близких по качеству изображений.
 В рамках испытаний системы разработчики NVIDIA сперва создали низкокачественные видео, имитирующие съёмку с автомобильного регистратора, и обнаружили, что модель способна генерировать вполне связные видео в разрешении 512 x 1024 пикселей длительностью в несколько минут. Впрочем, ИИ может работать и с более высоким разрешением в различных визуальных стилях. В частности, команда NVIDIA произвела огромное множество видео в разрешении 1280 x 2048, используя для их создания исключительно текстовые описания. Весь итоговый продукт в данном формате содержал 113 кадров, то есть при рендеринге с 24 кадрами в секунду продолжительность видео составляла около 4,7 секунды. Пока что попытки создания более длинных видео в данном разрешении заканчиваются «поломкой» логики изображений и резко более странными результатами.
В рамках испытаний системы разработчики NVIDIA сперва создали низкокачественные видео, имитирующие съёмку с автомобильного регистратора, и обнаружили, что модель способна генерировать вполне связные видео в разрешении 512 x 1024 пикселей длительностью в несколько минут. Впрочем, ИИ может работать и с более высоким разрешением в различных визуальных стилях. В частности, команда NVIDIA произвела огромное множество видео в разрешении 1280 x 2048, используя для их создания исключительно текстовые описания. Весь итоговый продукт в данном формате содержал 113 кадров, то есть при рендеринге с 24 кадрами в секунду продолжительность видео составляла около 4,7 секунды. Пока что попытки создания более длинных видео в данном разрешении заканчиваются «поломкой» логики изображений и резко более странными результатами.
 В NVIDIA признают, что на данном этапе ИИ-модель по-прежнему создаёт явно искусственные видео с огромным множеством странных ошибок. Кроме того, в большинстве анимаций невооружённым глазом заметна разница между ключевыми и промежуточными кадрами: зачастую это отражается в неуместном ускорении или замедлении движений объекта. Однако даже в таком виде работы ИИ NVIDIA выглядят гораздо более качественными и правдоподобными, чем, например, жуткие кадры, сгенерированные ModelScope, вроде Уилла Смита, который с пугающим энтузиазмом поедает спагетти. Разработчики также работают над созданием публичной системы, которая позволит генерировать видео на основе собственных изображений пользователей. Впрочем, пока что разработки на базе LDM для NVIDIA – это скорее исследовательский проект, который всё ещё далёк от полноценного коммерческого продукта.
В NVIDIA признают, что на данном этапе ИИ-модель по-прежнему создаёт явно искусственные видео с огромным множеством странных ошибок. Кроме того, в большинстве анимаций невооружённым глазом заметна разница между ключевыми и промежуточными кадрами: зачастую это отражается в неуместном ускорении или замедлении движений объекта. Однако даже в таком виде работы ИИ NVIDIA выглядят гораздо более качественными и правдоподобными, чем, например, жуткие кадры, сгенерированные ModelScope, вроде Уилла Смита, который с пугающим энтузиазмом поедает спагетти. Разработчики также работают над созданием публичной системы, которая позволит генерировать видео на основе собственных изображений пользователей. Впрочем, пока что разработки на базе LDM для NVIDIA – это скорее исследовательский проект, который всё ещё далёк от полноценного коммерческого продукта.
 Тем не менее, по мнению экспертов, человечеству не придётся ждать слишком долго, чтобы получить обширные системы разнообразных ИИ-моделей, которые позволят комбинировать различные алгоритмы для создания полноценных форм контента: от анимированных детских книг с озвучкой и музыкальным сопровождением до сложнейших 3D сценариев для VR-видеоигр.
Тем не менее, по мнению экспертов, человечеству не придётся ждать слишком долго, чтобы получить обширные системы разнообразных ИИ-моделей, которые позволят комбинировать различные алгоритмы для создания полноценных форм контента: от анимированных детских книг с озвучкой и музыкальным сопровождением до сложнейших 3D сценариев для VR-видеоигр.
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models / Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, Karsten Kreis